Przygotowanie do tagowania
Na poniższym zrzucie ekranu podświetlone są różne obszary aplikacji.
Treść dokumentu jest wyświetlana po lewej stronie. Rozdziały można wybierać z listy rozwijanej „Rozdział”. Jeśli rozdział zawiera tabele, tabele wybranego rozdziału można wybrać z listy rozwijanej „Tabela”. Po wybraniu tabeli jest ona wyświetlana w zakładce „Tagowanie Tabeli”. Już oznaczone elementy w powyższym przykładzie są podświetlone na zielono. Kliknij komórkę tabeli, aby wyświetlić wszystkie metainformacje dotyczące znacznika XBRL w polu „Właściwości Tagowania" poniżej tabeli. Wszystkie elementy wczytanej taksonomii są wyświetlane po prawej stronie w strukturze zdefiniowanej w taksonomii.
Oznaczanie tabel PDF

Informacja
Te kroki należy wykonać przed oznaczeniem tabel w plikach PDF. Ten krok nie jest wymagany w przypadku innych formatów Word, ePub (InDesign) i XHTML.
Tagowanie PDF działa trochę inaczej niż np. MS Word. Nie można automatycznie wykrywać tabel w PDF. Po otwarciu Taggera i załadowaniu pliku zostaniesz przekierowany do zakładki Podgląd . Jeśli spojrzysz na kartę Tagowanie Tabeli , zobaczysz, że jest pusta. Tabele w pliku PDF należy zdefiniować po otwarciu dokumentu (jednorazowo). Aby to zrobić, musisz otworzyć plik PDF oraz wczytać taksonomię i następnie wykonać poniższe kroki:
- Przejdź do zakładki Podgląd
- Wybierz z menu odpowiednią stronę dokumentu z tabelą do otagowania
-
Zaznacz i zaznacz całą tabelę w podglądzie za pomocą kursora myszy. Proszę użyć małych niebieskich kropek, aby przesunąć zaznaczenie, jeśli nie jest możliwe dokładne zaznaczenie kursorem myszy. Najlepiej jeśli tabela jest zaznaczona bez nagłówka całej tabeli, ale z nagłówkami kolumn.
-
Przeciągnij i upuść wybrany abstrakt taksonomii na zaznaczenie (żółty na powyższym obrazku). Tabela jest teraz oznaczona jako całość niebieską ramką:
- Wróć do zakładki Tagowanie Tabeli. Tabela jest już dostępna:
Ikony

ta ikona służy do dodawania rozszerzeń XBRL do wybranych komórek

ta ikona służy do edycji hierarchii wymiarów

ta ikona służy do kastomizacji hierarchii wymiarów

ta ikona jest używana do dodawania elementów wymiaru

ta ikona służy do dodawania rozszerzeń XBRL do wszystkich nieoznakowanych komórek

ta ikona służy do usuwania zaznaczonych mapowań / można też zaznaczyć komórkę i nacisnąć klawisz DEL na klawiaturze

ta ikona służy do usuwania wszystkich mapowań tabeli

ta ikona służy do oznaczania przypisów

ta ikona służy do automatycznego tagowania wybranych komórek

ta ikona służy do przeglądania ustawień Tabeli

ta ikona służy do zmiany kolejności wierszy
Tabele
Oznaczanie wartości w tabeli jest prostą kwestią przeciągania i upuszczania (Drag&Drop). Po zidentyfikowaniu elementu z taksonomii XBRL odpowiadającego danej komórce w tabeli można go przeciągnąć z prawej części aplikacji na cyfrę, która ma zostać oznaczona. Po pomyślnym oznaczeniu komórka zostanie podświetlona na zielono.
Jeden element taksonomii można przypisać do różnych okresów:
Tagger próbuje wstępnie automatycznie określić okres lub datę dla danego tagu na podstawie wartości w pierwszym wierszu kolumny (przy odpowiednim zaznaczeniu tabeli zwykle jest to nagłówek kolumny). Na przykład dla wartości 33,197 jest oznaczony okres od 1 stycznia 2018 roku do 31 grudniu 2018 roku, podczas gdy dla wartości 17,279 analogiczny okres jest oznaczony dla roku 2017.
Szczegóły tagowania można sprawdzić w zakładce „Tagi” i „Właściwości Tagowania” po kliknięciu komórki. Wyświetlane wartości dziedziczą swoje określone ustawienia z tabeli; wartości domyślne ustawień tabeli są dziedziczone z ustawień dokumentu. W razie potrzeby wartości można zmienić w oknie dialogowym „Właściwości Tagowania” dla poszczególnych komórek. Ta zakładka może być również używana do celów audytowych: w sekcji „Audyt” możesz zobaczyć datę i godzinę ostatniej zmiany oraz nazwę użytkownika, który dokonał zmiany. Tagi można usunąć w zakładce „Tagi” klikając na czerwony znak "x".
Tagowanie automatyczne
Po kliknięciu przycisku „Otaguj wybrane komórki za pomocą Auto-Tagowania”

, cała tabela zostanie sprawdzona i automatycznie otagowana w komórkach, dla których zostaną odalezione dopasowania.
Po zakończeniu tagowania zostanie wyświetlony następujący komunikat:
Za pomocą opcji Dokładność Auto-Tagowania i Tryb Auto-Tagowania, użytkownicy mogą zdefiniować, w jaki sposób zostanie wykonane automatyczne tagowanie: np. czy należy używać sztucznej inteligencji i czy porównanie nazw powinno być ścisłe, czy nie.
Znakowanie tabel podzielonych na dwie strony
Czasami tabele są podzielone na dwie osobne strony, a etykiety wierszy są dostępne tylko na pierwszej stronie:
Prowadzi to do tego, że tabeli na drugiej stronie nie można prawidłowo oznaczyć:
Aby temu zaradzić, do ustawień tabeli wprowadzono dwie nowe opcje :
RowLabelColumnId : można tego użyć, jeśli etykiety wierszy tabeli nie są pierwszym wierszem tabeli. Po prostu ustaw identyfikator kolumny (na podstawie 0) kolumny zawierającej etykiety.
RowLabelTableId : Wybierz tabelę z listy rozwijanej, która zawiera etykiety wierszy dla tej tabeli (w razie potrzeby można jej użyć w połączeniu z RowLabelColumnId)
W przypadku tabel dwustronicowych wystarczy wybrać tabelę zawierającą etykiety:

Obie tabele MUSZĄ mieć taką samą liczbę wierszy ORAZ kolejność wierszy MUSI być taka sama.
Po najechaniu kursorem na wiersz lub spojrzeniu na szczegóły komórki zostanie wyświetlona etykieta pobrana z pierwszej tabeli:
Możliwe jest również otagowanie całego wiersza łącznie z pierwszą kolumną:
Tagowanie dwóch tabel na jednej stronie
Niektóre tabele przedstawiają dwie różne tabele jako jedną „fizyczną” tabelę (przykład poniżej: aktywa i pasywa). Niektóre mechanizmy Taggera zaprojektowane, aby ułatwić życie klientom, mogą tu stanowić problem, na przykład automatyczne wykrywanie etykiet wierszy i przyległych komórek.
Aby umożliwić poprawne otagowanie takiej tabeli, wprowadzono ustawienie tabeli: TwoInOneTableSplitColumnId
Ustawienia tego można użyć do zdefiniowania drugiej kolumny RowHeader, zawierającej nazwy wierszy dla komórek w kolejnych kolumnach, skutecznie dzieląc tabelę na dwie.
Rozszerzenia i zakotwiczenie
Rozszerzenia
Ujawnienia dotyczące konkretnego podmiotu, które nie są dostępne w standardowej taksonomii, należy oznaczyć jako rozszerzenia taksonomii.
Rozszerzenie taksonomii jest dozwolone tylko wtedy, gdy taksonomia nie zawiera odpowiedniego elementu i jeśli podstawowy element taksonomii prowadziłby do błędnej interpretacji. Aby określić istniejące pozycje taksonomii, z którymi rozszerzenie jest semantycznie powiązane, należy użyć tak zwanego „kotwiczenia”.
Aby utworzyć nowe rozszerzenie dla pozycji , należy zaznaczyć komórkę, a następnie kliknąć przycisk
( „Dodaj rozszerzenie XBRL do wybranej komórki”). Komórka zostanie podświetlona na żółto, a obok wartości pojawi się zielony krzyżyk. Możliwe jest również kliknięcie przycisku
("Dodaj rozszerzenie XBRL do wszystkich nieotagowanych komórek ): w rezultacie wszystkie nieoznakowane komórki zostaną podświetlone na żółto i oznaczone zielonym krzyżykiem (należy pamiętać, że może być trudno odróżnić komórki, które są już zakotwiczone od tych, które są jeszcze nie edytowane, ponieważ wszystkie mają ten sam kolor podświetlenia).
Następnie przejdź do zakładki „Właściwości Rozszerzenia Taksonomii” i wybierz / dodaj odpowiednie atrybuty. Obecnie można edytować następujące atrybuty elementu: typ salda; typ elementu; etykieta; nazwa; typ okresu; powód rozszerzenia.
Rodzaj salda: debetowe, kredytowe lub nieznane
Nazwa elementu: nazwa techniczna elementu (CamelCase)
Typ elementu: wybierz typ (pieniężny, na akcję, ciąg znaków, blok tekstowy itp.)
Etykieta elementu: etykieta elementu (jest kopiowana z tabeli)
Typ okresu: natychmiastowy, czas trwania lub nieznany
Powód rozszerzenia: tutaj możesz opisać powody, dla których nie można zastosować standardowej koncepcji taksonomii
Element sumowania: określa, czy element jest sumą innych elementów, w którym to przypadku kotwice nie są potrzebne. Jeśli wybrany element jest sumą, wyświetlane jest „prawda”; zmienia się automatycznie po utworzeniu obliczenia.
Kotwiczenie
Teraz utworzone rozszerzenie musi być powiązane z podstawową taksonomią. Elementy taksonomii rozszerzenia muszą być zawsze zakotwiczone w elementach taksonomii ESEF, z wyjątkiem elementów odpowiadających sumom częściowym (Element sumowania: prawda). Istnieją dwie możliwości:
element rozszerzenia taksonomii ma węższe znaczenie księgowe lub zakres niż element w podstawowej taksonomii
element rozszerzenia taksonomii ma szersze znaczenie lub zakres rachunkowości niż element podstawowej taksonomii
Na przykład pozycja „Very specific AMANA paid in capital” w powyższej tabeli znajduje się w sekcji „Kapitał własny” w tabeli, więc można ją przypisać do „Inne udziały kapitałowe” w taksonomii ESEF. Aby zakotwiczyć element, przeciągnij i upuść odpowiednie elementy podstawowej taksonomii do pola „Zakotwiczenie”.
Dodatkowe/wielojęzyczne etykiety
Poprzez opcje wyświetlania "Display Options" w dokumencie podglądu XHTML w przeglądarce, możliwe jest wyświetlanie znaczników ESEF w dowolnym dostępnym w taksonomii języku.
Jeśli chcesz, aby rozszerzenia miały etykiety w różnych językach, a nie tylko w domyślnym języku raportu, możesz dodać etykiety dla dodatkowych języków w sekcji Właściwości Tagowania:
Tagowanie elementów Member
Tabele z kilkoma kolumnami np. zestawienie zmian w kapitale własnym wymagają zarówno tagowania poszczególnych pozycji, jak i tagowania kolumn (members).
W pierwszej kolejności tagujemy poszczególne pozycje. Następnie zaznaczamy kolumnę do tagowania, wybieramy element z taksonomii XBRL i przeciągnij go z prawej części aplikacji do wybranej kolumny. Po pomyślnym oznaczeniu kolumna zostanie podświetlona.
"Members" w taksonomii ESEF są reprezentowani przez specjalną ikonę i mają etykietę [member]:
Aby utworzyć nowe rozszerzenie dla wybranej kolumny , wybierz kolumnę i kliknij przycisk
(„Dodaj Element Wymiaru”).
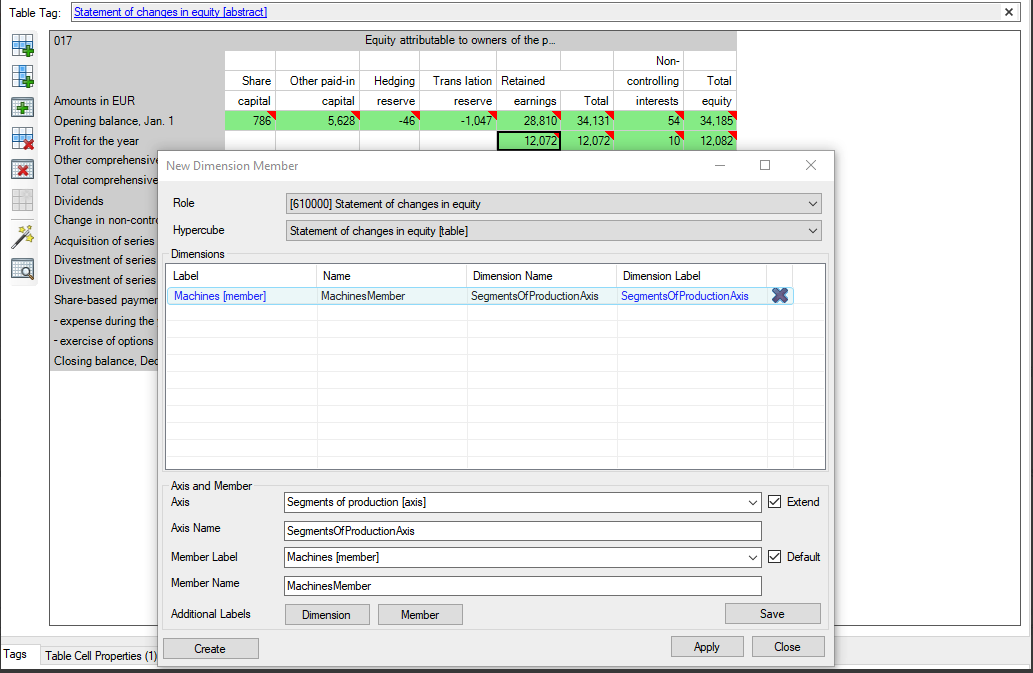
Aby utworzyć wymiar rozszerzony, kliknij najpierw przycisk „Utwórz”. Możesz wybrać istniejącą oś wybranego hipersześcianu lub utworzyć nową. Pamiętaj, że możesz utworzyć tylko jednego nowego memebera na raz. Kombinacja elementów pozycji nie jest możliwa.
Użyj istniejącej osi:
Jeśli nie musisz tworzyć nowej osi, po prostu wybierz istniejącą i dodaj nowy element. W razie potrzeby możesz zmienić nazwę techniczną. Po zakończeniu kliknij „Zapisz”.
Utwórz nową oś:
Aby utworzyć nową oś zaznacz pole wyboru „Rozszerz” i dodaj etykietę. W razie potrzeby możesz zmienić nazwę techniczną. Każda oś potrzebuje jednego elementu „Domyślny”, który będzie miał zastosowanie do wszystkich elementów w tabeli, które nie zostały wyraźnie przypisane do elementu tego konkretnego wymiaru. Zaznacz pole „Domyślne” przy elemencie, który jest domyślny dla Twojej osi rozszerzonej. Po zakończeniu kliknij „Zapisz”.
Dodaj dodatkowe etykiety:
Po kliknięciu „Zapisz” możesz dodać dodatkowe etykiety dla wielu języków zarówno do osi, jak i do elementu. Wystarczy dwukrotnie kliknąć kombinację na liście, a następnie kliknąć przycisk „Wymiar” lub „Member”, aby dodać nowe etykiety.
Uwagi i obowiązkowe elementy
Oprócz oznaczania wartości w tabelach możliwe jest również tagowanie tekstu odpowiednimi elementami z taksonomii. AMANA XBRL Tagger umożliwia znakowanie całych rozdziałów / podrozdziałów dokumentu. Aby kontynuować tagowanie tekstowe, wybierz zakładkę Tagowanie Tekstu. Aby oznaczyć rozdział elementem z taksonomii, znajdź element w taksonomii, a następnie przeciągnij i upuść go na wybrany rozdział. Po pomyślnym oznaczeniu nazwa elementu i etykieta zostaną wyświetlone obok nazwy rozdziału. Jeśli rozdział jest otagowany, wszystkie podrozdziały staną się automatycznie częścią tagu.
ESEF może wymagać tagowania poszczególnych słów lub zdań (np. Nazwa podmiotu raportującego). Jeśli element nie jest dostępny w sekcji „Oznaczanie bloków tekstu”, istnieją dwie możliwości dodania go do listy:
Utwórz kontrolę treści lub dodaj komentarz.
Aby utworzyć kontrolę zawartości:
- otwórz plik w MS Word i przejdź do zakładki „Developer”.
Jeśli nie możesz znaleźć karty „Deweloper”, przejdź do: Plik-> Opcje-> Dostosuj Wstążkę, a następnie aktywuj kartę „Developer”
Wybierz wymagany tekst i wstaw kontrolkę zawartości.
Jeśli „Tryb projektowania” jest aktywny, kontrolki zawartości są zawsze wyświetlane.
Otwórz plik MS Word w Taggerze i przejdź do zakładki "Oznaczanie tekstu" -> Treść tekstowa jest teraz wyświetlana.
Alternatywnie możesz po prostu dodać komentarz w pliku Word. Wtedy Tagger wyświetli również skomentowany tekst.
Zakładka „Podgląd”
„Podgląd” wyświetla podgląd konwersji HTML dla aktualnie wybranego rozdziału.
Jeśli wczytany jest dokument EPUB lub PDF, możesz oznaczyć teksty i otagować je bezpośrednio tutaj.
Aby oznaczyć przypisy (dodatkowe informacje o liczbach lub wierszach / kolumnach w tabelach), w podglądzie należy zaznaczyć odpowiedni tekst przypisu. Następnie należy kliknąć ikonę zarządzania przypisami dla treści

. W oknie dialogowym „Zarządzaj przypisem” wszystkie komórki związane z przypisem należy zaznaczyć, wybierając odpowiednią komórkę, a następnie klikając

.
Wymagane jest wybranie wielu komórek tabeli dla przypisu, co zależy od pozycji przypisu:
- Jeśli przypis zostanie dodany do pojedynczej komórki wartości tabeli, należy zaznaczyć tylko komórkę tabeli.
- Jeśli przypis zostanie dodany do nagłówka / etykiety wiersza, wszystkie komórki w wierszu muszą zostać zaznaczone.
- Jeśli przypis zostanie dodany do nagłówka / etykiety kolumny, wszystkie komórki w kolumnie muszą zostać zaznaczone.
- Jeśli przypis zostanie dodany do pełnej tabeli (np. W nagłówku tabeli), wszystkie komórki tabeli muszą zostać zaznaczone.
Nawiasy / Wartości w przypisach
Fakty, które należą do tabeli, ale fizycznie nie są jej częścią, można oznaczyć jako przypisy lub w nawiasach, co oznacza dodatkowe informacje dołączone do tabeli. Te informacje również muszą zostać ujawnione.
Można to osiągnąć, po prostu zaznaczając tekst zawarty w oknie podglądu oraz przeciągając i upuszczając żądany element XBRL na zaznaczony tekst, jak pokazano poniżej:
W drugim kroku ten element również musi być zakotwiczony do tabeli, do której należy. Można to osiągnąć, po prostu przeciągając i upuszczając tag tabeli na element:
Wynikowa baza prezentacji dla powyższego przykładu będzie wyglądać następująco:
Definiowanie kalkulacji w tabelach
Sumy częściowe (element sumowania = true) nie muszą być zakotwiczone w koncepcji taksonomii ESEF. Możesz użyć zakładki Kalkulacja, aby zdefiniować elementy sumy częściowej, definiując sumy wybranej komórki.
Aby dodać obliczenia, najpierw wybierz sumę częściową, a następnie aktywuj sumowanie („Wybór elementów: włącz”). Następnie wybierz odpowiednie komórki i kliknij „Dodaj wybrane”. Wybrane pozycje zostaną wymienione w kolejności alfabetycznej.
Kiedy wszystkie wymagane elementy podsumowania są dodane, kliknij ponownie przycisk "Wybór elementów:", aby zmienić go na „wyłącz” i kontynuować z innymi komórkami. Możliwe jest wybranie sum z różnych tabel. Po prostu zostaw przycisk "Wybór elementów: włącz" i zmień tabelę, aby dodać kolejne pozycje z innej tabeli.
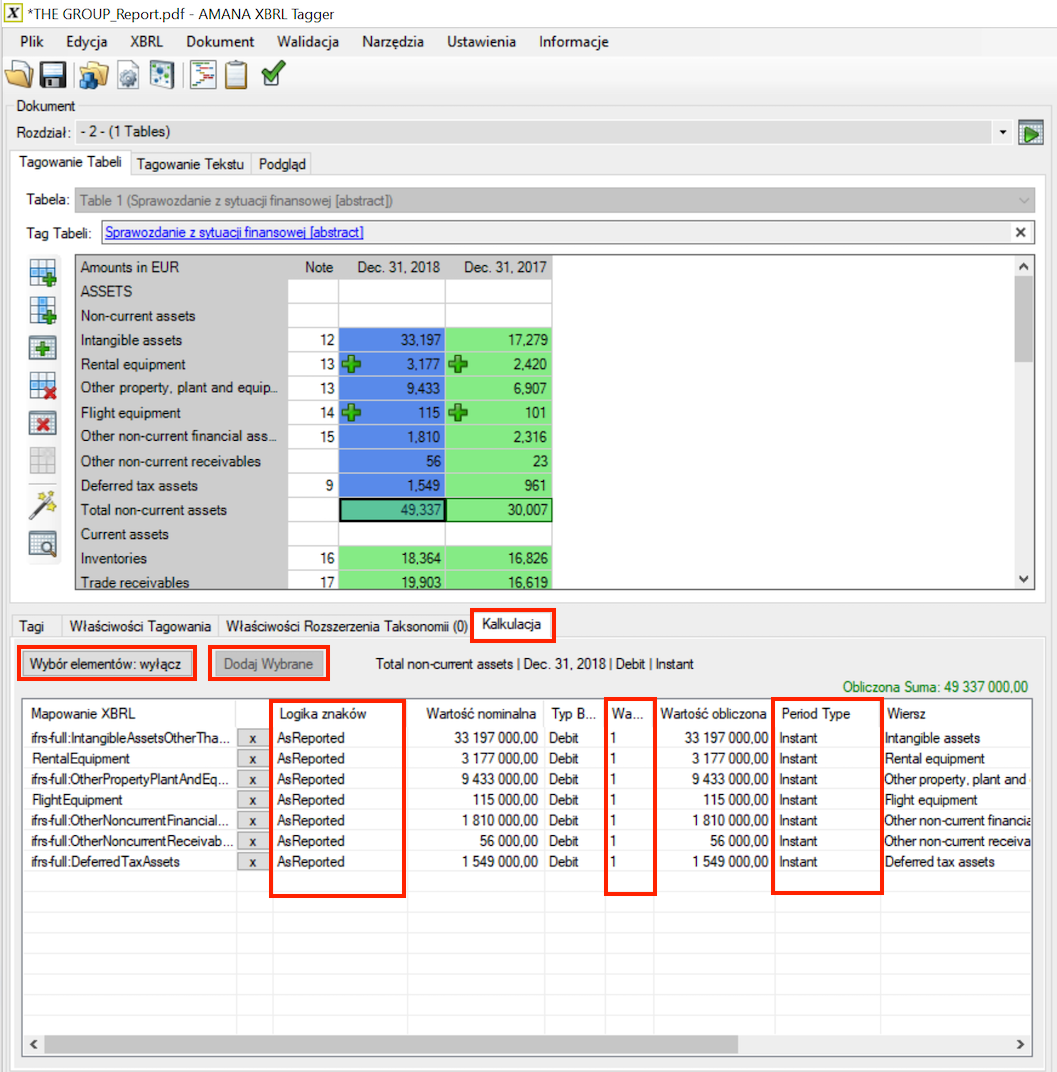
Zakładka Kalkulacja pozwala również na wyświetlanie informacji pomocnych w tworzeniu właściwych relacji obliczeniowych. Bieżącą obliczoną sumę można zobaczyć w prawym górnym rogu plus deltę, jeśli obliczenie nie zgadza się z wartością sumy. Obok przycisku „Dodaj Wybrane” znajdują się informacje o sumie: Etykieta wiersza i kolumny, typ salda i typ okresu.
Więcej informacji na temat logiki znaków Sign Logic i wag znajduje się w następnej sekcji. Oba ustawienia można zmienić dla pozycji na liście w zakładce Kalkulacja.

Należy pamiętać, że nie można dodawać kalkulacji w tabeli Zestawienie zmian w kapitale własnym
Kalkulacje mają pewne ograniczenia wynikające ze specyfikacji XBRL, stąd nie jest możliwe tworzenie obliczeń, które:
- odnoszą się do różnych wymiarów
- zawierają inny typ okresu niż suma
- są obliczeniami takimi jak np. saldo początkowe + zmiana w okresie = saldo końcowe
Logika znaków (określanie wartości ujemnych)
Wprowadzenie
W niektórych przypadkach logika znaków zastosowana w raporcie różni się od wymagań regulatora. Ogólnie taksonomie XBRL, takie jak np. taksonomia IFRS, wymagają dla pozycji takich jak np. „Koszt sprzedaży” raportowania ich jako liczb dodatnich. Jeśli pozycja jest prezentowana jako liczba ujemna, może być konieczne odwrócenie jej znaku w raporcie XBRL, ale wyświetlenie jej nadal jako „ujemnej”. W niektórych systemach księgowych wszystkie pozycje kredytowe w raporcie mają znak ujemny, podczas gdy regulator oczekuje, że wartości te zostaną zgłoszone ze znakiem dodatnim.
Najważniejsze jest to, że: pozycje mogą być wyświetlane inaczej, niż ich wartość w zależności od rodzaju salda. Jeśli raport wyświetla -500 dla pozycji debetowej (np. Koszt sprzedaży ), zwykle oznacza to, że wartość wynosi 500 (Koszt) i jest tylko wyświetlana z minusem, aby jego związek z innymi pozycjami w raporcie był jaśniejszy bez konieczności patrzenia na typ bilansowy danego tagu. Koszt raportowany jako ujemny w praktyce oznaczałby dochód (uwaga: mogą być sytuacje w których tak jest ze względu na np. korekty).
W poniższej tabeli wyjaśniono znaczenie atrybutu salda (zwanego również BalanceType) zgodnie z ich zastosowaniem w różnych sprawozdaniach finansowych.
Atrybut bilansowy
|
Sprawozdanie z sytuacji finansowej (bilans) |
Zestawienie całkowitych dochodów, zysków lub strat |
Sprawozdanie z przepływów pieniężnych |
| Debet |
Aktywa |
Koszt |
Wpływ gotówki |
| Kredyt |
Pasywa / Kapitał |
Przychód |
Wypływ gotówki |
Ponadto pozycje takie jak Zysk (strata) wyraźnie dopuszczają wartości ujemne ze względu na ich znaczenie pojęciowe i odpowiednią etykietę. Domyślnym / pozytywnym znaczeniem tego pojęcia jest zysk, ale wyświetlenie wartości ujemnej może oznaczać po prostu stratę, a nie błąd SignLogic. Inne przykłady to:
- Zysk (strata)
- Zysk operacyjny (strata)
- Zysk (strata) przed opodatkowaniem
- Zysk brutto
- Zysk na akcję (strata)
- Przepływy pieniężne z (wykorzystane w)
- Wpływy pieniężne (wypływy)
- Dochód (koszt)
- Przychody (koszty) finansowe
- Zwiększenia/Zmniejszenia
Przykład
Spójrzmy na przykład:
- Przychody finansowe są oznaczone tagiem: ifrs-full: FinancialIncome (Credit)
- Koszty finansowe są oznaczone tagiem: ifrs-full: FinanceCosts (Debit)
- "Net financial items" jest rozszerzeniem typu salda kredytowego, które można również nazwać Zysk finansowy (strata)
Wystarczy spojrzeć na tabelę, aby łatwo obliczyć, że dana firma (w kolumnie 3) miała przychód finansowy w wysokości 394, wydatki 1184, co daje łącznie 790 jako strata finansowa. Łatwo jest z raportu wyczytać w jaki sposób zostałoby to obliczone: 394-1184 = -790. Łatwo też zauważyć, że w drugiej kolumnie jest oczywisty błąd w raporcie. Wyświetlana wartość powinna być 313 bez znaku -.
Gdybyśmy spojrzeli na tę samą tabelę w widoku danych XBRL, wyglądałoby to tak:
Jest oczywiste, że w tej tabeli mamy różne znaki. Podczas gdy test:NetFinancialItems ma znak minus, zarówno przychody finansowe, jak i koszty finansowe są dodatnie. Jeśli spojrzymy na właściwość BalanceType tych znaczników w taksonpmii XBRL, ma to sens:
- Przychód finansowy to Credit, który przekłada się na + 394 mln
- Koszt finansowy to Debit, co przekłada się na -1184 mln
- NetFinancialItems to Credit, co oznacza -790 mln
Mając to na uwadze, możemy wykonać te same obliczenia, co powyżej.
Właściwość SignLogic
Aby prawidłowo połączyć dwa widoki (raport i widok XBRL) opisane powyżej, XBRL posiada właściwość logiki znaków o nazwie SignLogic. Informuje narzędzia XBRL, jak interpetować wartość wyświetlaną na raporcie. Chociaż można to ogólnie wywnioskować z konceptu, nie jest to coś, co można całkowicie zautomatyzować. Prawdziwe znaczenie wyświetlanej części sprawozdania finansowego nie może być właściwie zinterpretowane przez zwykłe oprogramowanie (jeszcze).
XBRL Tagger oferuje wiele sposobów rozwiązania tego problemu poprzez odwrócenie znaku liczby.
Podczas generowania dokumentu wynikowego iXBRL istnieje możliwość odwrócenia znaku wartości na podstawie atrybutu salda oznakowanego elementu. Aby uzyskać więcej informacji, zobacz sekcję Generowanie raportu iXBRL.
Dodatkowo istnieje możliwość zdefiniowania logiki znaków dla pojedynczej komórki. Logika znaków zastosowana do wybranej komórki jest pokazana w kolumnie „Logika znaku” w zakładce „Właściwości Tagowania”.
Możliwe są następujące wartości SignLogic:
- None : nie zostanie zastosowana żadna specjalna logika znaków. Znak można nadpisać np. Gdy przy generowaniu raportu jest aktywne ustawienie „Odwróć znak pozycji obciążeniowej” i oznakowany element posiada saldo debetowe.
- AsReported: wartość będzie zawsze dodawana do dokumentu iXBRL z tym samym znakiem, co znak w raporcie. Nawet jeśli ustawienie „Odwróć znak pozycji debetowej” jest aktywne podczas generowania raportu, znak nie zostanie zmieniony, nawet jeśli oznakowany element ma saldo debetowe.
- Reverse : znak zostanie odwrócony. Wartości ujemne zostaną przedstawione jako wartości dodatnie w dokumencie iXBRL i odwrotnie.
- AlwaysPositive : wartość zawsze będzie podawana ze znakiem dodatnim.
- AlwaysNegative : wartość zawsze będzie podawana ze znakiem ujemnym.
Spójrzmy na wiersze z naszej tabeli z przykładu:
Koncept |
BalanceType |
Wyświetlana wartość |
SignLogic |
Wartość XBRL |
Przychody finansowe
|
Credit |
394 |
AlwaysPositive |
394 |
| Koszty finansowe |
Debit |
-1184 |
Reverse |
1184 |
Zysk finansowy (strata)
|
Credit
|
-790 |
AsReported |
-790 |
Obliczania i waga
Wybrana logika znaków SignLogic jest bardzo ważna dla walidacji relacji obliczeniowych kalkulacji. W naszym przykładzie obliczenia wyglądałyby następująco:
Zysk finansowy (strata) = Przychody finasowe - Koszty finansowe
Atrybut wagi jest ustawiany automatycznie w zależności od typu bilansowego i nie należy go zmieniać!
Jeśli teraz spojrzymy na nasz przykład, mamy:
-790 * 1 (AsReported) = 394 * 1 (AlwaysPositive) - (-1184 * -1 (Reverse)) ↔ -790 = 394-1184
Jeśli wykonamy te same obliczenia dla drugiej kolumny, walidacja obliczeń nie zadziała i ponownie zobaczymy oczywisty błąd, którego być może jeszcze nie widzieliśmy, ale musimy go poprawić.
Status
Aby zapewnić lepszy przegląd procesu znakowania, można ustawić jeden z trzech dostępnych poziomów statusu dla oznaczonych komórek:
- In Edit w edycji (komórka jest podświetlona na czerwono)
- Review Pending oczekuje na sprawdzenie (komórka jest podświetlona na żółto)
- Final koniec (komórka jest podświetlona na zielono)
Można to zrobić, klikając prawym przyciskiem myszy oznaczoną komórkę (lub grupę komórek) i wybierając odpowiedni status w sekcji „Ustaw Status”:
Gdy używana jest funkcja automatycznego tagowania (
Otaguj wybrane komórki za pomocą Auto-Tagowania), wszystkie automatycznie oznaczone komórki są podświetlone na żółto. Status można później zmienić ręcznie. To samo dotyczy rozszerzeń.
AMANA XBRL Tagger umożliwia użytkownikom definiowanie domyślnych poziomów statusu dla ręcznego znakowania, rozszerzeń i automatycznego tagowania. Aby zmienić ustawienia domyślne, przejdź do Ustawienia → Opcje i wybierz poziomy statusu z dostępnych list rozwijanych.
Aby zapisać dokument, kliknij przycisk Zapisz Dokument w głównym oknie Taggera:
Jeśli pracujesz z plikiem MS Word, tagi są zapisywane bezpośrednio w pliku MS Word. Następnym razem, gdy otworzysz oznakowany plik MS Word w Taggerze, tagi zostaną załadowane automatycznie.
Jeśli tagujesz plik PDF lub ePub i klikniesz „Zapisz Dokument”, tagi zostaną zapisane w oddzielnym pliku technicznym *.mapping:
Dopóki plik ten ma taką samą nazwę jak plik pdf i znajduje się w tym samym folderze, tagi zostaną załadowane automatycznie, gdy otworzysz plik pdf w XBRL Tagger.
Eksport / import tagowania (roll forward)
Istnieje kilka opcji kopiowania tagów z jednego raportu do drugiego. Typowe przypadki to:
- Zastąpienie otagowanego dokumentu PDF nowszą wersją, z mniejszymi zmianami (np. literówki, zmiany liczb w tabelach). W takim przypadku nie jest wymagana żadna specjalna funkcjonalność, wystarczy trzymać plik * .pdfmapping w tym samym folderze i zastąpić plik PDF nową wersją. Wszystkie tagi powinny zostać przywrócone.
- Kopiowanie tagowania z raportu do nowego w następnym roku (roll-forward). Tagger jest w stanie przywrócić tagowanie poprzez podmianę pliku PDF (jak powyżej) lub przy użyciu funkcji „Archiwizuj Mapowania / Przywróć Mapowania”. Czasem w przypadku zmian np. dodatkowych lub zmienionych stron Tagger nie jest w stanie automatycznie, ponownie odnaleźć wszystkich tabel, aby przywrócić do nich tagi. Wymagane wtedy jest ręczne przywrócenie tagów tabeli ze Schowka Mapowania, jak opisano w rozdziale Schowek Mapowania. Jest to wymagane tylko w przypadku dokumentów PDF lub ePub, w przypadku plików MS Word, jeśli używany jest ten sam plik Word, wszystkie znaczniki pozostają w samym dokumencie Word.
- Kopiowanie tagowania z jednej wersji językowej raportu do innej. Tagger jest w stanie przywrócić około 95% tagów, jeśli struktura dokumentu i tabeli nie różni się zbytnio poprzez podmianę pliku PDF lub przy użyciu Schowka Mapowania.
- Kopiowanie tagowania z jednego formatu dokumentu do innego, np. z MS Word do PDF. Jest to możliwe na podstawie przy użyciu Schowka Mapowania.
Kopie zapasowe / przywracanie
Po otagowaniu raportu można zapisać tagi w oddzielnym pliku, korzystając z opcji „Archiwizuj Mapowania” w sekcji „Dokument”:
Tagi są zapisywane w osobnym pliku .ixbak na komputerze:
Aby przywrócić tagi z poprzedniego roku, otwórz „czysty” plik w Taggerze i przejdź do „Dokument” → „Przywróć Mapowania”:
Wybierz zapisany lokalnie plik .ixbak i kliknij „Otwórz”:
Należy pamiętać, że proces przywracania zakończy się sukcesem tylko wtedy, gdy struktura dokumentu nie zmieni się drastycznie: tabele pozostaną prawie takie same (wartości mogą oczywiście ulec zmianie i jeśli zostanie dodany nowy wiersz, to również powinno być OK) i są wyświetlane na tych samych stronach dokumentu.
Jeśli niektórych tagów nie można przywrócić, są one kopiowane do Schowka Mapowań i można je przypisać ręcznie.
Schowek Mapowania (Clipboard Mapping)
Jeśli chcesz skopiować tagi np. z dokumentu MS Word do pliku PDF lub niektóre tagi nie zostaną przywrócone automatycznie podczas korzystania z opcji przywracania z kopi zapasowej, używamy Schowka Mapowania.
Kopiowanie pomiędzy dwoma otwartymi dokumentami w Tagger:
Preferowaną metodą kopiowania mapowań między dwoma dokumentami, czy to
Roll-Forward, czy przenoszeniem mapowań z dokumentu w jednnym
języku na inny, jest użycie Schowka Mapowań. Można jednocześnie otworzyć dwa Tagger-y, jeden z dokumentem, który już zawiera mapowania, a drugi z nowym dokumentem i użyć Schowka Mapowań do przenoszenia mapowań.
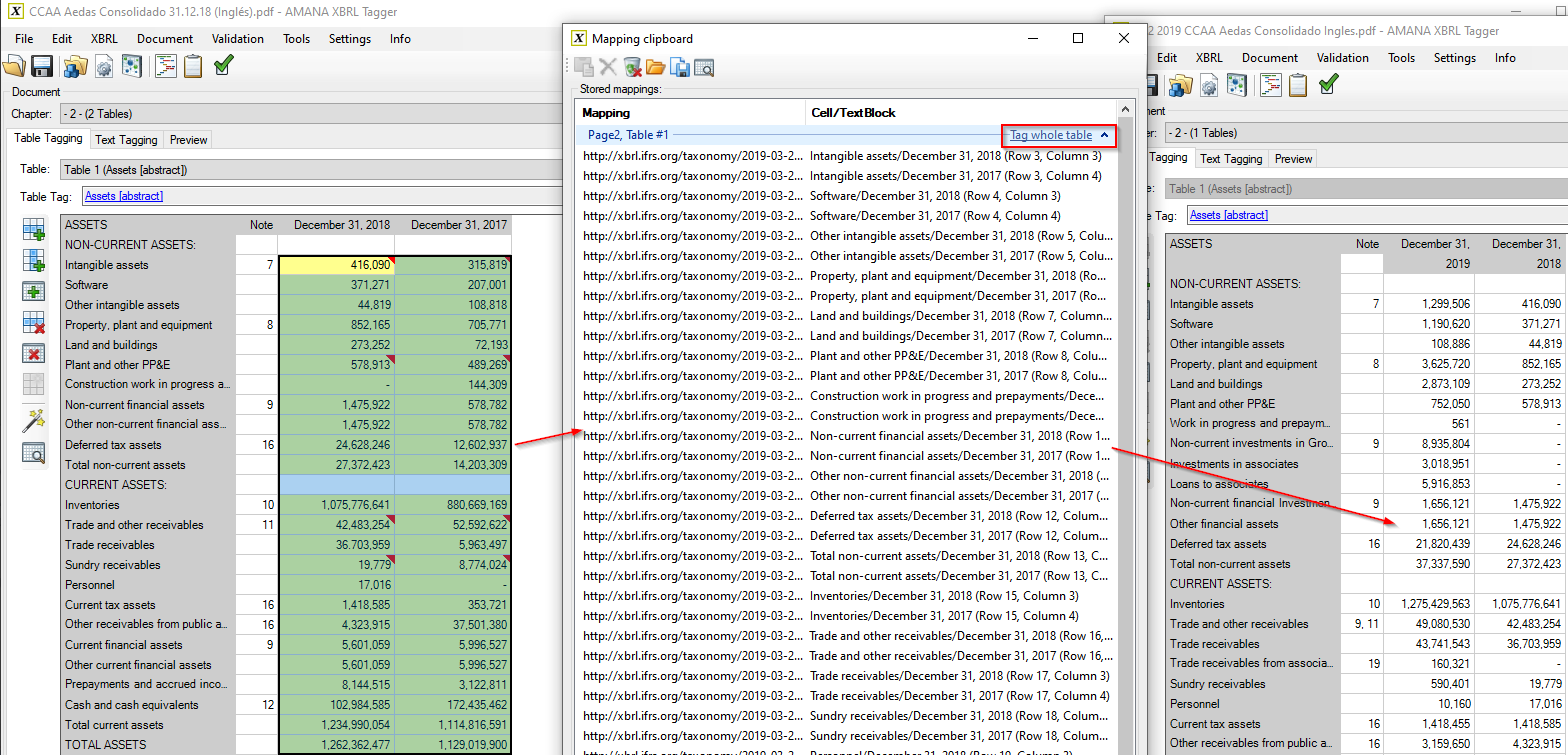
Po prostu wybierz i skopiuj wszystkie mapowania z tabeli w dokumencie źródłowym, przełącz się na tę samą tabelę w dokumencie docelowym, otwórz Schoek Mapowań i kliknij przycisk „Tag whole table”. Wszystkie mapowania, w tym obliczenia oraz wszystkie metadane, zostaną przeniesione. Jeśli nowa tabela zawiera dodatkowe wiersze, zwykle pozostaną one puste, a mapowania zostaną przywrócone tylko do komórek rozpoznanych przez Tagger.
Jeśli kopiujesz mapowania między raportami, które mają różne języki, może być konieczne dostosowanie etykiet i formatów walut. Tagger pomaga obsługiwać kopiowanie i wklejanie, wystarczy upewnić się, że ustawienia dokumentu docelowego dokumentu są prawidłowe. Jeśli Tagger wykryje, że dokument docelowy ma inny język raportowania, niż dokument źródłowy, etykiety zostaną zaktualizowane z odpowiedniego wiersza, a formaty zostaną zaktualizowane przy użyciu domyślnego formatu z ustawień dokumentu.
Zachowywanie tagowań ze Schowka Mapowań
Jeśli chcesz skopiować tagi z pliku MS Word do pliku PDF:
- Skopiuj tagi w oznaczonych tabelach (możesz zaznaczyć całą tabelę i nacisnąć Ctrl + C). Rób to tabela po tabeli, aż wszystko zostanie skopiowane do Schowka Mapowań:
- Zapisz plik schowka na swoim komputerze:
- Otwórz plik PDF w Taggerze
- Wybierz obszar tabeli i ustaw znacznik tabeli:
- Otwórz Menedżera Clipoboard i załaduj plik .tcf:
- Kliknij „Tag whole table”, aby skopiować wszystkie tagi do wybranej tabeli. Potwierdź i postępuj w ten sam sposób z pozostałymi tabelami w pliku PDF.
Zastępowanie plików
Tej opcji można użyć, jeśli oznaczanie przeprowadzono w pliku PDF, który wymaga drobnych poprawek.
Jeśli wystąpiły drobne zmiany w pliku PDF i znaczniki muszą zostać skopiowane ze starego pliku PDF z tagami do nowego dostosowanego pliku PDF, po prostu zastąp stary plik nowym. Upewnij się, że nazwa nowego pliku jest taka sama jak nazwa pliku .mapping (z wyjątkiem „.mapping”) i że zarówno nowy plik PDF, jak i plik .mapping znajdują się w tym samym folderze. Usuń stary plik PDF.
Archiwizacja/ Przywracanie Mapowań
Jeśli dokument wymaga odtworzenia, np. z systemu takiego jak SmartNotes, wszystkie utworzone tagi nie są już częścią tego dokumentu. Aby zachować istniejące tagi i informacje, Tagger umożliwia utworzenie zewnętrznego pliku kopii zapasowej (.ixbak), który zapisuje wszystkie informacje oddzielnie od pliku.
Aby utworzyć zewnętrzny plik kopii zapasowej, kliknij Dokument → Archiwizuj Mapowania.
Po wczytaniu nowego dokumentu informacje z pliku kopii zapasowej można przywrócić do nowego dokumentu, wybierając wcześniej zapisany plik. Należy pamiętać, że poważne zmiany w dokumencie mogą uniemożliwić Taggerowi przywrócenie wszystkich informacji z pliku kopii zapasowej.
Aby przywrócić dane z zewnętrznego pliku kopii zapasowej, kliknij Dokument → Przywróć Mapowania.
W razie potrzeby przywrócenia mapowania można wybrać jeden z następujących trybów przywracania komórek:
- Indeks i Nazwa Wiersza/Kolumny — jeśli struktura i język dokumentu pozostają takie same.
- Indeks Wiersza/Kolumny - jeśli np. język się zmienia, podczas gdy struktura pozostaje taka sama.
- Nazwa Wiersza/Kolumny - w przypadku zmiany struktury, np. w tabeli jest wiele nowych wierszy, podczas gdy nazwy starych wierszy pozostają takie same.
Należy pamiętać, że proces przywracania zakończy się pomyślnie tylko wtedy, gdy struktura dokumentu nie zmieni się drastycznie: tabele pozostaną prawie takie same (wartości mogą się oczywiście zmienić, a jeśli zostanie dodany nowy wiersz, również powinno być OK) i są wyświetlane na te same strony pliku. Jeśli niektórych znaczników nie można przywrócić, są one kopiowane do Schowka Mapowań i można je przypisać ręcznie.
Tagowanie hierarchii
Oprócz raportu rocznego, który można przeglądać w przeglądarce jako ESEF, każdy emitent tworzy również własną taksonomię, wraz z bazą prezentacyjmą, która powinna odzwierciedlać strukturę raportu i może być wizualizowana za pomocą narzędzi XBRL.
W Taggerze 1.5 użytkownicy mieli już możliwość przypisania elementów "abstract" do istniejących tagów w celu stworzenia struktury podobnej do poniższej dla np. sprawozdania z sytuacji finansowej:

Ta struktura była ograniczona do jednego poziomu poniżej elementu głównego. W Taggerze od wersji 1.6 możliwe jest tagowanie całej struktury.
Aby to osiągnąć, przeciągnij i upuść żądany abstract do zakresu komórek, które chcesz zgrupować:
W oknie dialogowym kliknij TAK, jeśli chcesz odzwierciedlić hierarchię z bazy prezentacyjnej ESMA lub „Pnly Abstract”, aby utworzyć strukturę, jak w Tagger v1.5:

Wynikowa wizualizacja bazy prezentacyjnej z tego samego raportu będzie teraz wyglądać następująco:

Raport Mapowań
„Raport Mapowań” pobiera wszystkie oznaczone dane i informacje z dokumentu i tworzy plik Excel zawierający szczegółowe informacje dla każdego mapowania. Można to wykorzystać do weryfikacji oznaczonych elementów.
Aby wygenerować raport mapowania, kliknij Dokument → Raport Mapowań.
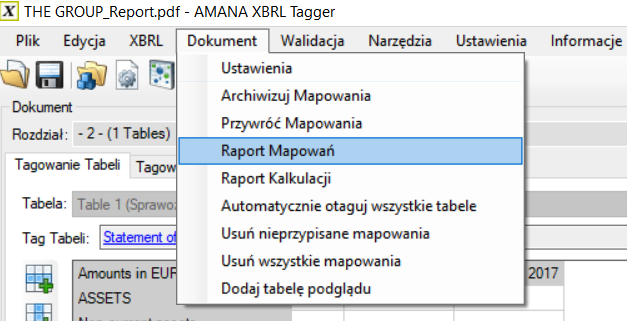

W niektórych przypadkach raport mapowania może być nieco przeładowany informacjami. Od wersji 1.7 i nowszych możliwe jest wybranie tylko tych kolumn, które chcesz umieścić w raporcie mapowania:
Raport Kalkulacji
Raport z obliczeń zawiera przegląd wszystkich obliczeń w raporcie.
Aby wygenerować raport mapowania, kliknij Dokument → Raport Kalkulacji.
Tagowanie Ukrytych Elementów
Niektóre wymagania raportowania iXBRL mogą wymagać użycia ukrytych elementów. Elementy ukryte to wartości, które są ręcznie dodawane do raportu XBRL, ale nie są częścią raportu źródłowego, więc nie można ich bezpośrednio oznaczyć. W przypadku ESEF ukryte elementy nie są zalecane. Aby włączyć ukryte elementy w raporcie, po prostu aktywuj ustawienie:
Tagger będzie miał teraz dodatkową zakładkę, w której można dodawać i oznaczać ukryte elementy:
Aby dodać wartość, kliknij prawym przyciskiem myszy i wybierz „Dodaj”:
Po utworzeniu wartości można ją oznaczyć w zwykły sposób, przeciągając i upuszczając zancznik z taksonomii:
Tagowanie Multi-Taxonomy
W niektórych jurysdykcjach władze lokalne wymagają, aby raporty ESEF były znakowane nie tylko elementami taksonomii ESEF, ale także dodatkowymi elementami lokalnej taksonomii. Rozszerzenie taksonomii jest nadal wykonywane tylko w taksonomii ESEF, ale sam raport zawiera znaczniki z więcej niż jednej taksonomii. Te wymagania dotyczące wielu taksonomii mogą stać się bardziej powszechne w przyszłości. W wersji 1.7 XBRL Tagger obsługuje tagowanie raportów za pomocą dwóch lub więcej taksonomii.
1. Aby rozpocząć, wystarczy jak zwykle załadować raport i taksonomię ESEF.
2. Następnie kliknij przycisk XBRL/Otwórz Wczytaj Dodatkową Taksonomię.
5. Niektóre taksonomie mogą wymagać elementu zwanego Target, który mówi XBRL, że jeden dokument iXBRL zawiera dwa różne dokumenty XBRL. W Taggerze element Target można ustawić w oknie dialogowym XBRL/Zarządzaj Dodatkowymi Taksonomiami:
6. Jeśli teraz wygenerujesz dokument wynikowy, znaczniki każdej taksonomii zostaną zweryfikowane zgodnie z walidacjami, które są częścią taksonomii źródłowej. W folderze raportów znajdziesz również dwie instancje XBRL, po jednej dla każdego Target.
Scalanie dokumentów
Wersja 1.5 Taggera wprowadza możliwość scalenia wielu dokumentów formatu iXBRL w jeden, np. Jeśli:
- Wielu użytkowników pracuje nad podzestawami oryginalnego dokumentu
- Główna część sprawozdania jest w oddzielnym dokumencie, a pozostała część dokumentu jest załączana jako osobny dokument
- Używamy kilku dokumentów źródłowych, nawet jeśli mają one różne typy plików
Dzięki nowej funkcji możliwe jest:
- Scalanie dokumentów z różnych typów plików źródłowych
- Zachowanie stylów oryginalnych dokumentów, nawet jeśli bardzo się różnią
- Scalanie taksonomii, np. jeśli różne dokumenty mają tylko podzbiory docelowego rozszerzenia taksonomii
Aby scalić dokumenty, wykonaj następujące kroki:
1. Utwórz iXBRL ze wszystkich plików, które mają zostać scalone:
3. Kliknij przycisk
Dodaj
i wybierz dokumenty typu .xhtml (wygenerowane w kroku 1), które mają zostać scalone:
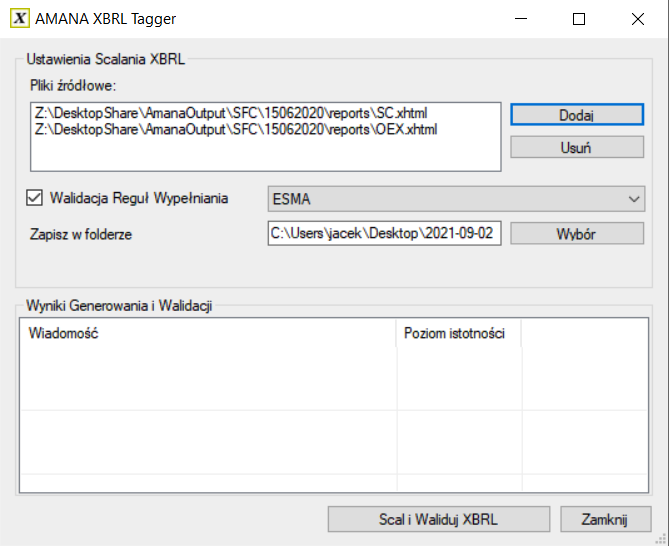
4. Otwórz wygenerowany plik .xhtml w folderze wyjściowym. Rozszerzona taksonomia MUSI znajdować się w strukturze folderów, którą tworzy Tagger:
5. Kliknij Scal i Waliduj XBRL . Wynik scalania może wyglądać następująco:

Walidacja
Walidacja podczas tagowania
XBRL Tagger ma dwa typy walidacji:
1. Walidacje w locie, które można wykonać podczas edycji dokumentu
2. Walidacja podczas generowania raportu, która jest wykonywana automatycznie podczas tworzenia dokumentu wynikowego
Poniżej znajduje się przegląd różnych weryfikacji, z którymi możesz się spotkać.
Walidacje w locie
Rodzaj |
Opis |
Waga |
Identyfikator podmiotu raportu: brak kodu LEI

|
Ważny dokument ESEF wymaga odpowiedniego kodu LEI podmiotu dokonującego zgłoszenia : www.gleif.org |
Ostrzeżenie na testach
Błąd na produkcji
|
Żaden element tabeli nie został otagowany

|
Każda tabela z odwzorowaniami wymaga oznakowania elementu tabeli. |
Błąd |
Stan komórki „w edycji” lub „oczekuje na przegląd”

|
Tylko przepływ pracy: nie wszystkie komórki mają ostateczny stan. |
Ostrzeżenie |
Komórka nie ma tagowania

|
Komórka w tabeli ze znacznikiem tabeli nie ma przypisania. Wszystkie komórki powinny być oznaczone!
|
Ostrzeżenie na testach
Błąd na produkcji
|
Komórka nie jest częścią kalkulacji

|
Wszystkie oznaczone komórki powinny być być częścią relacji obliczeniowej
|
Ostrzeżenie na testach
Błąd na produkcji
|
Zduplikowane tagowanie

|
Tagi mogą pojawić się w dokumencie tylko dwukrotnie, jeśli kontekst jest inny lub wartość jest równa |
Błąd |
Element rozszerzenia nie ma zakotwiczenia

|
Każde rozszerzenie wymaga co najmniej jednej kotwicy, chyba że jest to suma relacji obliczeniowej |
Błąd |
Raportowana suma nie jest zgodna z obliczoną sumą

|
Zaokrąglona suma relacji obliczeń nie jest równa zaokrąglonej obliczonej sumie. Nie musi być ważne! |
Ostrzeżenie |
Wybrany format jest niezgodny z tagiem

|
Zastosowano zły format bazowy, np. Format daty dla wartości pieniężnej |
Błąd |
Wartość jest nieprawidłowa dla danego formatu |
Wybranego formatu nie można zastosować do wartości tagu. |
Błąd |
Nie znaleziono znacznika w taksonomii
|
Oznaczony element nie został znaleziony w taksonomii. Inna wersja taksonomii? |
Błąd |
Brak elementu pozycji

|
Komórka ma oznaczone elementy wymiaru, ale nie ma elementu pozycji.
|
Błąd |
Niepoprawne wymiary |
Każde mapowanie w tabeli musi zawierać te same wymiary |
Błąd |
|
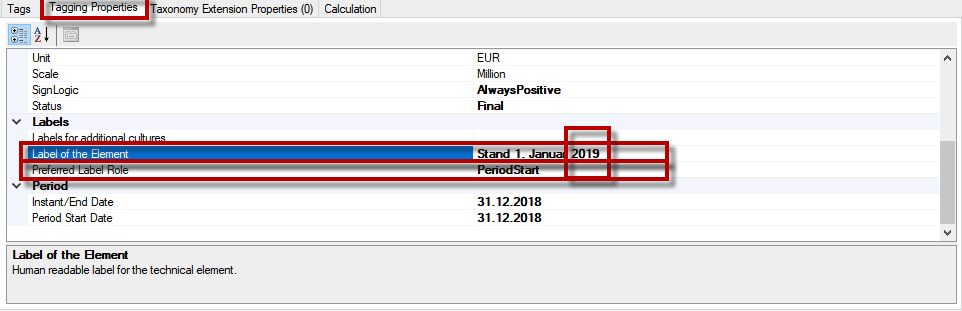
Zduplikowane etykiety
|
Zduplikowane ostrzeżenie lub błąd etykiety jest wyświetlane w komórkach z takimi samymi kombinacjami tagów, ale z różnymi nazwami (etykietami). Na przykład „ifrs-full:kapitał własny” może być oznaczony w bilansie jako „całkowity kapitał własny”, a w zestawieniu zmian w kapitale własnym etykietą „kapitał własny na dzień 01.01.2019” i „kapitał własny na dzień 31.12.2019 r. ”. W takim przypadku dla tego samego znacznika dostarczane są trzy różne etykiety. Aby rozróżnić znaczenie różnych etykiet, wymagane jest ustawienie tak zwanej roli etykiety. Najczęstsze role etykiet to (próbki w nawiasie):
Etykieta standardowa (kapitał własny)
Etykieta ogółem (całkowity kapitał własny)
Etykieta początku okresu / końca okresu (kapitał własny na początku/na końcu okresu).
Etykieta pełna (kapitał określony przez naturę).
Ważne jest, aby wyrównać wszystkie etykiety używane w raporcie dla wszystkich wartości, które są oznaczone tym samym elementem. Dozwolona jest tylko jedna etykieta na rolę. Zwykle oznacza to również usunięcie odniesień do dat z etykiety początku i końca okresu „Kapitał na koniec okresu” zamiast „Kapitał na 31.12.2019”, ponieważ dwie etykiety końca okresu (31.12.2019 i 31.12.2020 ) nie są możliwy.
Zmień preferowane role etykiet i etykiety w obszarze Właściwości komórki tabeli:
|
Błąd
|
|
Zduplikowane rozszerzenia
|
Błąd zduplikowanego rozszerzenia jest wyświetlany, gdy komórki z rozszerzeniami mają różne właściwości: np. różne kotwice w bieżącym roku poprzednim; inna logika znaku dla każdej komórki.
|
|
|
Typ Okresu
|
Typ okresu elementów ifrs-full jest określony w taksonomii. Pozycje z różnymi typami okresów nie mogą być uwzględnione w jednym wyliczeniu:
|
|
Walidacje podczas generowania raportów iXBRL
Rodzaj |
Opis |
Akcja |
Utworzono puste rozszerzenie taksonomii XBRL |
Czy raport wymaga rozszerzenia taksonomii? |
Skonfiguruj prawidłowe ustawienie dokumentu. |
Wszystkie inne typy w folderze generowania raportów |
Błędy podczas tworzenia raportu. |
Jeśli nie ma błędów walidacji podczas walidacji w locie: Skontaktuj się z AMANA |
Specyfikacja wymiaru wystąpienia XBRL |
Nieprawidłowy plik wyjściowy |
Jeśli nie ma błędów walidacji podczas walidacji w locie: Skontaktuj się z AMANA |
Walidacja zasad zgłoszenia |
Zasady składania dokumentów przez organy regulacyjne nie są spełnione. |
Upewnij się, że wybrano odpowiednie zasady archiwizacji (np. ESMA dla ESEF). Sprawdź zasady w instrukcji zgłoszenia regulatora. |
Specyfikacja instancji XBRL 2.1 |
Przekonwertowany plik XBRL jest nieprawidłowy. |
Zignoruj ostrzeżenia (np. Błędy relacji obliczeniowych). W razie wątpliwości skontaktuj się z AMANA. |
Specyfikacja taksonomii XBRL 2.1 |
Rozszerzona taksonomia jest nieprawidłowa |
Skontaktuj się z AMANA |
Formuła wystąpienia XBRL 1.0.0 |
Reguły z taksonomii nie są spełnione |
Jeśli to możliwe, zignoruj ostrzeżenia. Jeśli to możliwe, popraw błędy. W razie wątpliwości skontaktuj się z AMANA.
|
Publikacja raportów iXBRL ESEF
W kolejnych rozdziałach opisano sposób składania raportów ESEF do organów krajowych, zwanych oficjalnymi mechanizmami wyznaczonymi (OAM, np. rejestry przedsiębiorstw lub organy rynku finansowego). Należy pamiętać, że nawet jeśli RTS ESEF jest podobny we wszystkich krajach UE, mogą istnieć dodatkowe zasady w każdym kraju. Przed opublikowaniem raportu ESEF sprawdź swoje lokalne wymagania. Poniżej kilka ogólnych zasad i wyjaśnień, jak to zrobić. Należy pamiętać, że AMANA nie ponosi odpowiedzialności za treść i integralność samego raportu.
Lista kontrolna publikacji
Proszę sprawdzić poniższą listę przed wysłaniem jakiegokolwiek raportu ESEF do swojego audytora lub organu krajowego (OAM), aby uniknąć odrzucenia raportu ESEF.
1. XBRL Tagger nie wyświetla żadnych błędów podczas walidacji, a jedynie ostrzeżenia lub komunikaty informacyjne .
Proszę kliknąć "Waliduj dokument" w menu "Walidacja", ikona w lewym dolnym rogu musi być zielona.
2. Podczas generowania raportu iXBRL nie ma żadnych błędów w komunikatach sprawdzania poprawności, a ikona jest zielona.
Każdy nieprawidłowy raport XBRL zostanie natychmiast odrzucony przez audytora lub OAM. Aby zachować zgodność z ESEF RTS, wszystkie błędy walidacji muszą zostać poprawione. Ostrzeżenia należy przejrzeć, ale zazwyczaj można je zignorować.
3. Raport jest kompletny i zawiera wszystkie wymagane dokumenty, informacje i znaczniki zgodnie z ESEF RTS.
Oznacza to nie tylko otagowanie każdej liczby na głównych sprawozdaniach finansowych. MOŻE to również obejmować:
- Jednostkowe ORAZ skonsolidowane podstawowe sprawozdania finansowe i noty
- Sprawozdanie Zarządu
- Raport dotyczący ładu korporacyjnego
- Sprawozdanie rady nadzorczej
- Oświadczenie o odpowiedzialności
- Obowiązkowe tagi, takie jak nazwa podmiotu zgłaszającego, siedziba podmiotu itp.
- Opinia audytora
4. Wejściowy plik PDF, Word lub ePub jest całkowicie konwertowany do formatu XHTML, a wszystkie znaczniki i przekształcone wartości faktów są poprawne.
Aby to sprawdzić należy otworzyć plik company_preview.xhtml wygenerowany przez XBRL Tagger, zaznaczyć wszystkie tagi i porównać jego zawartość z plikiem wejściowym. Przejrzyj każdy tag i jego właściwości, takie jak data, wartość faktyczna, saldo, zakotwiczenie itp.
5. Przygotuj się do opublikowania pełnego pakietu ESEF.
W pakietach raportowania ESEF nie jest dozwolona przeglądarka/podgląd (skrypt) iXBRL. Podczas generowania raportu użyj pliku ZIP, który jest tworzony przez XBRL Tagger, nie zawiera on plików *.xbrl i company_preview.xhtm l. Zaleca się jednak opublikowanie raportu XHTML (i pakietu raportów ZIP) na stronie internetowej firmy poświęconej relacjom inwestorskim wraz z podglądem dla wygody. Poniżej znajdują się wyjaśnienia dla każdego pliku w pakiecie raportów.
6. Prześlij testowy raport do lokalnego OAM.
Wiele OAM oferuje możliwość przetestowania składania raportu ESEF w środowisku nieprodukcyjnym. Takie postępowanie gwarantuje, że dokumentacja zostanie zaakceptowana – należy pamiętać, że po tym, jak audytor potwierdzi raport ESEF w swojej opinii, późniejsza zmiana może nie być możliwa.
7. Rozważ opublikowanie raportu na swojej stronie korporacyjnych relacji inwestorskich.
Proces generowania i publikowania raportu ESEF
Ogólny proces tworzenia i publikacji raportów ESEF zależy od lokalnych wymagań. W wielu krajach raporty ESEF podlegają corocznemu audytowi, więc może być wymagane dołączenie opinii audytora do publikowanych dokumentów. Jednak opinia biegłego rewidenta musi zazwyczaj zawierać komentarz do samego raportu ESEF, co uniemożliwia jego zmianę po uzyskaniu opinii biegłego rewidenta - nie zaleca się w ogóle zmiany plików, które zostały wymienione w opinii biegłego rewidenta.
W celu skompilowania wielu części raportu w jeden plik XHTML, XBRL Tagger oferuje możliwość łączenia dokumentów w jeden pakiet raportów ESEF . W niektórych krajach (np. Niemcy) nadal wymagane jest publikowanie zbadanych sprawozdań finansowych w formacie PDF wraz z raportem ESEF.
Końcowy pakiet raportu ESEF
Nawet jeśli plik iXBRL jest pojedynczym plikiem XHTML, samo opublikowanie lub przesłanie tego pliku nie wystarczy. Zamiast tego należy opublikować pełny pakiet raportu. Poniższa tabela opisuje strukturę folderów i dokumentów, które muszą być opublikowane jako pakiet raportów ESEF, gdzie firma jest używana jako symbol zastępczy krótkiej nazwy dla podmiotu raportującego. Wcięcie reprezentuje hierarchię folderów.
Nazwa pliku/nazwa folderu |
Typ pliku |
Komentarz |
company.zip |
plik .zip
|
Główny plik ZIP, uważany za pakiet raportów. |
|
company
|
Folder |
Musi mieć taką samą nazwę jak plik ZIP, żaden inny folder/plik nie jest dozwolony na tym poziomie. |
|
|
META-INF |
Folder |
Folder zawierający metadane techniczne dla oprogramowania XBRL w celu prawidłowego prowadzenia raportu. |
|
|
|
taksonomyPackage.xml |
XML |
Metadane pakietu raportów |
|
|
|
catalog.xml |
XML |
Metadane techniczne do przekierowywania adresów URL do poniższego rozszerzenia taksonomii. |
|
|
company.com |
Folder |
Rozszerzenie taksonomii raportu |
|
|
|
xbrl |
Folder |
|
|
|
|
|
2020 |
Folder |
Rok do wskazania okresu sprawozdawczego. |
|
|
|
|
|
firma-2020-12-31.xsd |
XSD |
Zawiera taksonomię specyficzną dla firmy. |
|
|
|
|
|
firma-2020-12-31_cal.xml |
XML |
Obliczenia tabel |
|
|
|
|
|
firma-2020-12-31_def.xml |
XML |
Wymiary (np. zmiany w kapitale) |
|
|
|
|
|
firma-2020-12-31_lab-pl.xml |
XML |
Etykiety, gdzie „pl” reprezentuje język raportu. |
|
|
|
|
|
firma-2020-12-31_pre.xml |
XML |
Wizualne grupowanie oznaczonych elementów |
|
|
raports |
Folder |
Folder raportów zawierający co najmniej jeden oznaczony lub nieoznakowany plik XHTML. Niedopuszczalne jest dostarczanie plików podglądu (skryptów) wraz z pakietem raportu końcowego. |
|
|
|
company.xhtml |
XHTML |
Sam raport można otworzyć w przeglądarce internetowej. Musi istnieć co najmniej jeden XHTML. |
|
|
|
sprawozdanie_z_dzialalnosci_zarzadu.xhtml *
|
XHTML |
Każdy inny dodatkowy plik XHTML. Wszystkie pliki w folderze raportów są traktowane jako zestaw dokumentów. |
* Ten plik nie jest obowiązkowy. Reprezentuje każdy dodatkowy plik XHTML, który jest częścią raportu ESEF. Nie ma wymogu, aby każda część raportu była osobnym plikiem XHTML, ani aby mieć jeden plik XHTML.
Publikowanie z Previewer na swojej stronie
Po opublikowaniu raportu bez podglądu za pośrednictwem krajowego OAM, możesz rozważyć opublikowanie raportu xhtml wraz z podglądem na własnej stronie internetowej, aby zapewnić dodatkową wartość dla użytkowników. Aby było to możliwe, należy wziąć pod uwagę pewne kwestie techniczne.
Plik podglądu
Jeśli wybierzesz opcję „Internet” do tworzenia podglądu, rzeczywisty skrypt podglądu tPubhe jest hostowany zewnętrznie na CDN. Jeśli korzystasz z tej opcji, musisz upewnić się, że ta zawartość nie jest blokowana przez żaden mechanizm na Twoim serwerze internetowym.
Jeśli wybrałeś opcję „Pełny odgląd” do tworzenia podglądu, musisz umieścić skrypt podglądu (znajdujący się w folderze skryptów) lokalnie na swojej stronie internetowej i upewnić się, że jest dostępny.
Typ Mime
Aby skrypt podglądu działał poprawnie, typ zawartości hostowanego pliku xhtml musi być ustawiony na „application/xhtml+xml” :
Schowek Mapowania (Mapping Clipboard)
Wraz ze schowkiem mapowania, wprowadzamy nowe, potężne narzędzie, które może być używane do rozwiązywania wielu zadań:
- Wytnij, skopiuj i wklej istniejące tagi (w tym cofnij) za pomocą skrótów klawiaturowych, takich jak Ctrl + c i Ctrl + v
- Tworzenie kopii zapasowych i ponowne wykorzystywanie tagów z innych dokumentów, zwłaszcza rozszerzeń
- Przypisywanie mapowań, których nie udało się automatycznie przypisać z kopii zapasowej
- Przenoszenie mapowania z innego typu dokumentu
- Kopiowanie mapowań pomiędzy dokumentami
Aby rozpocząć, po prostu otwórz
Schowek Mapowania :
Wszystkie elementy, które zostały do tej pory dodane do schowka, na przykład za pomocą Ctrl + c, są wylistowane w oknie schowka:
Przywracanie tagów
Aby przywrócić tagi ze schowka, po prostu zaznacz komórkę, do której chcesz przywrócić znacznik, i kliknij dwukrotnie znacznik w schowku.
Jeśli chcesz przywrócić całą tabelę lub grupę komórek, zaznacz wszystkie komórki, które chcesz oznaczyć, jak na poniższym obrazku i kliknij „Tag whole table” odpowiednią grupę w schowku:
Kliknij Tak, aby potwierdzić, a wszystkie komórki zostaną oznaczone jednym kliknięciem.
Zwróć uwagę, że grupy można przywrócić tylko w przypadku wyboru o tym samym rozmiarze. Np. nie jest możliwe zaznaczenie czterech komórek, skopiowanie tagów za pomocą Ctrl + C i wklejenie ich do wybranych sześciu komórek.
Usuwanie tagów
Aby usunąć jeden lub więcej wybranych znaczników z listy, kliknij na ikonie
Usuń wybrane .
Aby usunąć wszystkie tagi, kliknij znajdujący się obok przycisk
Usuń wszystkie.
Zapisywanie tagów
Aby zapisać bieżący stan schowka do pliku Taggera (* .tcf), użyj przycisku
Zapisz .
Używanie plików zewnętrznych
Klikając opcję
Wczytaj istniejący plik mapowania, można również pobrać tagi ze źródeł zewnętrznych:

Źródła to:
- Pliki z tagami (.epub, .pdf, .word, .html)
- Kopie zapasowe tagów (.etm, .ixbak)
- Zapisane pliki schowka Taggera (.tcf)
Umożliwia to Taggerowi ponowne wykorzystanie tagów już utworzonych w różnych innych dokumentach, co jest przydatne, jeśli chcesz np. ponownie wykorzystać utworzone rozszerzenia. Po prostu utwórz raport bazowy lub dodaj wszystkie rozszerzenia do schowka i zapisz stan w pliku zewnętrznym. Ta funkcjonalność pozwala również na przywracanie tagów z innych formatów (np. .Word do .epub).
Możesz również filtrować listę według elementów rozszerzenia taksonomii:
Nieprzypisane mapowania (Unresolved Mappings)
Jeśli istnieją nieprzypisane mapowania, ponieważ struktura raportu uległa zbyt dużej zmianie, można je zaimportować do Schowka Mapowania:
Stamtąd można je przypisać lub usunąć:
Praca z wieloma dokumentami
Preferowaną metodą kopiowania mapowań między dwoma dokumentami, czy to
Roll-Forward, czy przenoszeniem mapowań z dokumentu w jednnym
języku na inny, jest użycie Schowka Mapowań. Można jednocześnie otworzyć dwa Tagger-y, jeden z dokumentem, który już zawiera mapowania, a drugi z nowym dokumentem i użyć Schowka Mapowań do przenoszenia mapowań.
Po prostu wybierz i skopiuj wszystkie mapowania z tabeli w dokumencie źródłowym, przełącz się na tę samą tabelę w dokumencie docelowym, otwórz Schoek Mapowań i kliknij przycisk „Tag whole table”. Wszystkie mapowania, w tym obliczenia oraz wszystkie metadane, zostaną przeniesione. Jeśli nowa tabela zawiera dodatkowe wiersze, zwykle pozostaną one puste, a mapowania zostaną przywrócone tylko do komórek rozpoznanych przez Tagger.
Jeśli kopiujesz mapowania między raportami, które mają różne języki, może być konieczne dostosowanie etykiet i formatów walut. Tagger pomaga obsługiwać kopiowanie i wklejanie, wystarczy upewnić się, że ustawienia dokumentu docelowego dokumentu są prawidłowe. Jeśli Tagger wykryje, że dokument docelowy ma inny język raportowania, niż dokument źródłowy, etykiety zostaną zaktualizowane z odpowiedniego wiersza, a formaty zostaną zaktualizowane przy użyciu domyślnego formatu z ustawień dokumentu.
Import raportów, które nie zostały utworzone za pomocą Taggera
Jeśli w pierwszym roku raportowania ESEF skorzystaliście Państwo z usługi ousourcingu, a teraz chcielibyście sami otagować swoje raporty? A może nie jesteście w pełni zadowoleni ze swojego dotychczasowego rozwiązania, ale nie chcecie zaczynać od nowa? Dzięki Taggerowi w wersji 1.7.1 możecie Państwo po prostu zaimportować utworzony i opublikowany pakiet ESEF do Taggera i łatwo przenieść wszystkie tagi i metadane do Taggera:
Po prostu otwórz pakiet ESEF w Tagger i plik PDF/Word/epub/HTML w drugim oknie Taggera. Użyj schowka mapowania, aby łatwo przenieść znaczniki z pakietu do dokumentu źródłowego otwartego za pomocą Taggera i możesz kontynuować pracę z tego miejsca. Działa to również jeśli raporty są w różnych językach.















